- Test performance across unseen layouts, suppliers and document variants
- Introduce new layouts and edge cases
- Apply production-scale document volumes to detect accuracy or performance degradation
A technical walkthrough of experimentation for production accuracy.
See exactly how Invofox iterates on pipeline design, measures accuracy at the field and document level, and improves extraction on real documents — not cherry-picked samples.
Powering document extraction for teams at




Why experimentation matters for production accuracy.
Document extraction is almost never perfect on the first run. Production-ready performance needs visibility into how schemas behave, where mismatches show up, and how each change moves the needle. Accuracy breaks for predictable reasons: mixed document types, layout variation, edge cases and schema drift.
-
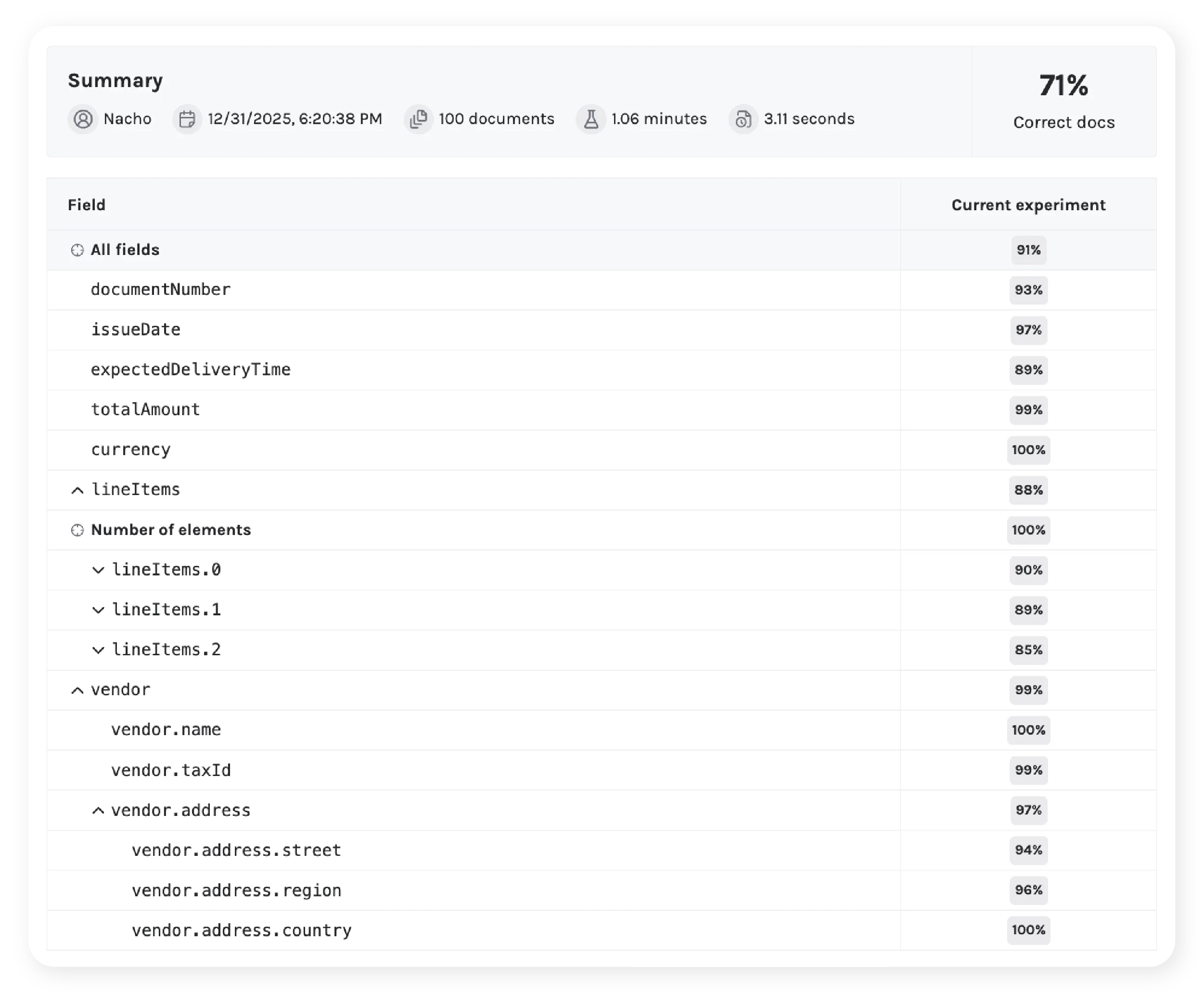
Measure accuracy at every level
Track field-level and document-level accuracy across every experiment.
How we measure accuracy -
Find the root cause of errors
Classify failures into explicit categories — no more guessing why accuracy dropped.
-
Compare changes with metrics
Every experiment is logged with concrete deltas, so you can see exactly what moved the needle.
-
Promote with confidence
Decide when a pipeline or model release is ready for production on your specific document set.
Establish an initial performance baseline.
Every experimentation cycle starts by running a simple extraction pipeline on client-provided documents and comparing the output against their ground truth. At this stage, the team can observe:
- Field-level accuracy across all extracted data
- A first signal of which fields are stable and which ones degrade
- A baseline to compare against future iterations
Inspect mismatches against ground truth.
For every experiment, extracted values are compared directly against ground truth. Mismatches are classified into explicit error categories so failure modes become visible and actionable.
Error categories
- OCR noise and character-level errors
- Semantically equivalent values expressed differently
- Incorrect field assignments or missing values
- Structural issues in nested fields or arrays
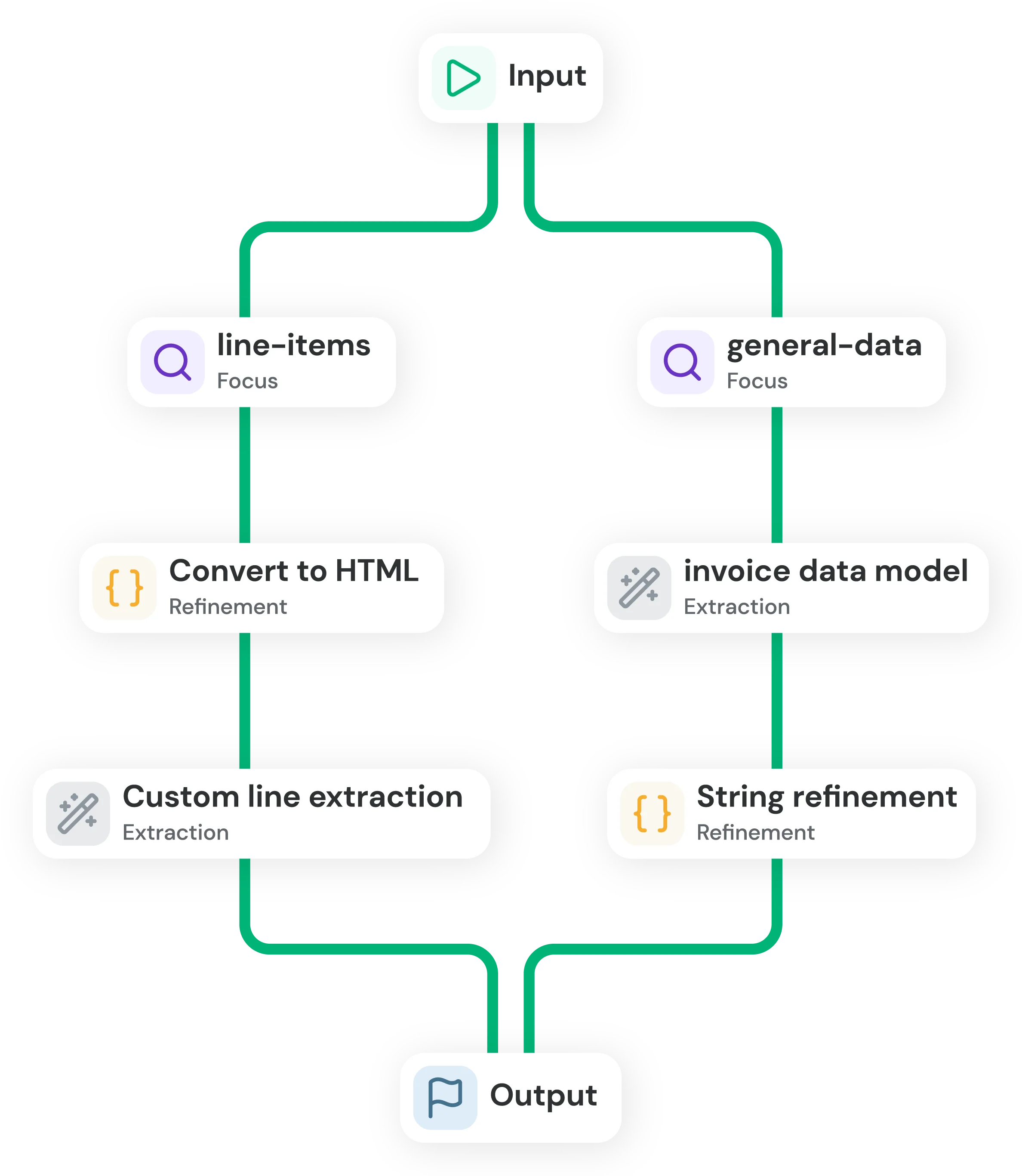
Targeted adjustments
-
Focused extraction
Split complex schemas so different models extract specific sections.
-
Input processing
Convert inputs to HTML or Markdown to align with model behavior.
-
Field-level refinement
Apply normalization, post-processing or custom logic to unstable fields.
-
Model specialization
Run different models, fine-tuned per document type, to improve accuracy.
Iterate until accuracy stabilises under production conditions.
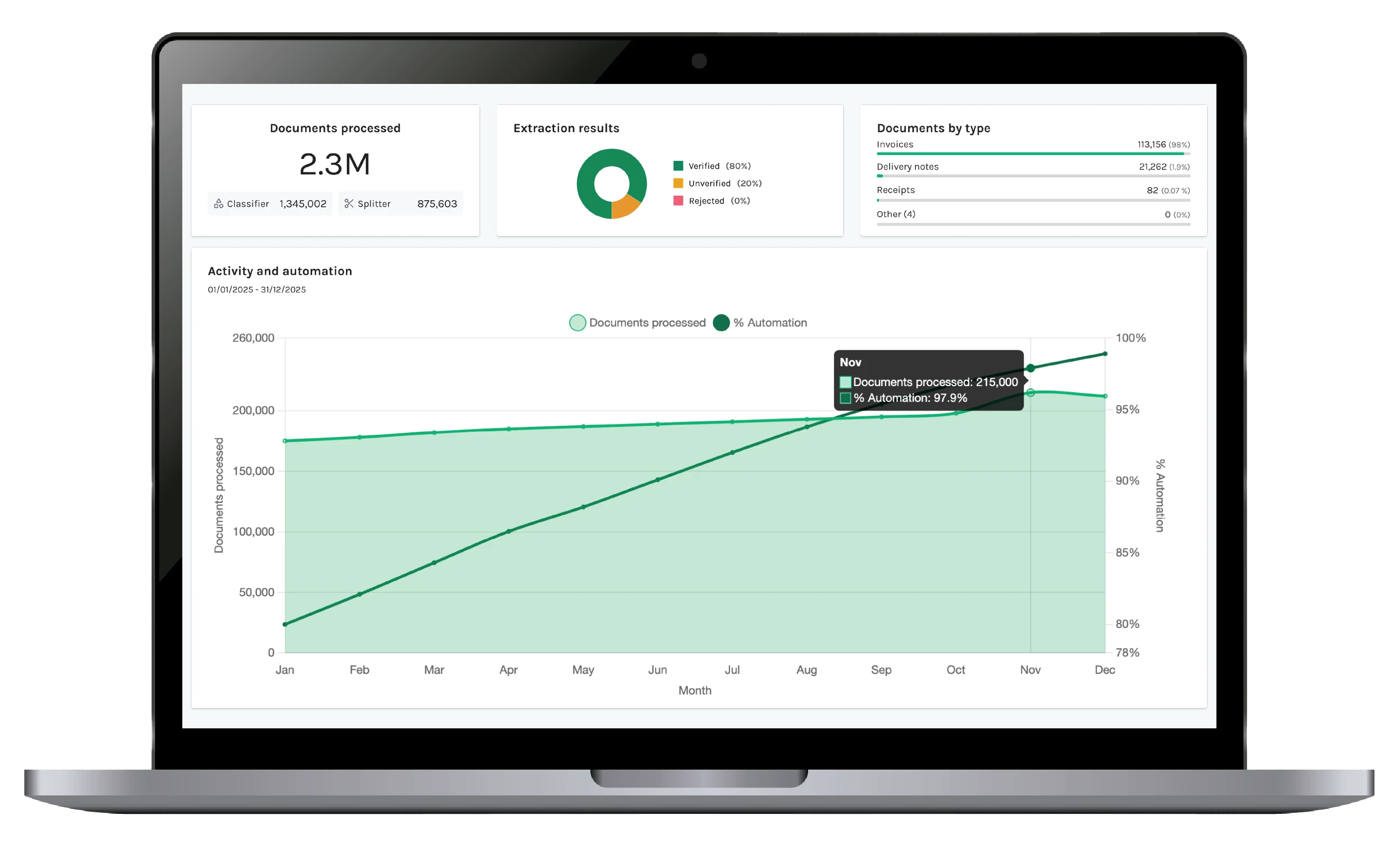
Pipelines aren't done when an experiment looks good in isolation — they're done when they hold up against the messy reality of production traffic.
- Incorporate client corrections and feedback into new iterations
- Monitor accuracy trends and detect regressions over time
- Automatically adapt pipelines as documents, layouts and requirements evolve
Experimentation is the backbone of production-grade document AI.
Most document AI is evaluated in isolation on clean inputs and ideal conditions. But production breaks when documents are mixed, layouts vary and schemas evolve. This workflow exists to close that gap — making experimentation an integral part of the platform, not an offline step. The result: teams that can…
-
Understand why accuracy changes
Every shift is traceable to a specific change — model, schema, layout, data.
-
Detect regressions before they hit production
Catch issues during experimentation, not after a customer reports them.
-
Validate across real document variability
Performance proven on real customer data, not cherry-picked samples.
-
Promote pipelines with confidence
Adopt new model releases safely, with clear evidence behind every change.
Related platform capabilities.
classifier.json
1 {
2 ··"question": "Classifier & Splitter",
3
4 ··"answer": "Separate and classify mixed, bundled documents so extraction starts from clean inputs. Learn more →"
5 }
Still have questions? Talk to us