- Probar el rendimiento sobre layouts, proveedores y variantes no vistas
- Introducir nuevos layouts y edge cases
- Aplicar volúmenes a escala productiva para detectar degradación
Walkthrough técnico de la experimentación para precisión en producción.
Mira exactamente cómo Invofox itera el diseño del pipeline, mide la precisión a nivel de campo y documento, y mejora la extracción sobre documentos reales — no muestras cherry-picked.
Procesamos documentos para equipos de




Por qué la experimentación importa para la precisión en producción.
La extracción de documentos casi nunca es perfecta a la primera. Llegar a precisión production-ready requiere visibilidad: cómo se comportan los esquemas, dónde aparecen los mismatches y cómo cada cambio mueve la aguja. La precisión se rompe por razones predecibles: tipos de documento mezclados, variación de layout, edge cases y schema drift.
-
Medir precisión a cada nivel
Precisión a nivel de campo y de documento en cada experimento.
Cómo medimos precisión -
Encontrar la causa raíz
Clasificar los fallos en categorías explícitas — sin adivinar por qué bajó la precisión.
-
Comparar cambios con métricas
Cada experimento queda logueado con deltas concretos — ves exactamente qué movió la aguja.
-
Promocionar con confianza
Decide cuándo un pipeline o release está listo para producción en tu set de documentos.
Establece una línea base de rendimiento.
Cada ciclo de experimentación arranca corriendo un pipeline simple sobre los documentos del cliente y comparando el output contra su ground truth. En este punto, el equipo ya puede observar:
- Precisión a nivel de campo sobre toda la data extraída
- Una primera señal de qué campos son estables y cuáles degradan
- Una línea base contra la que comparar las siguientes iteraciones
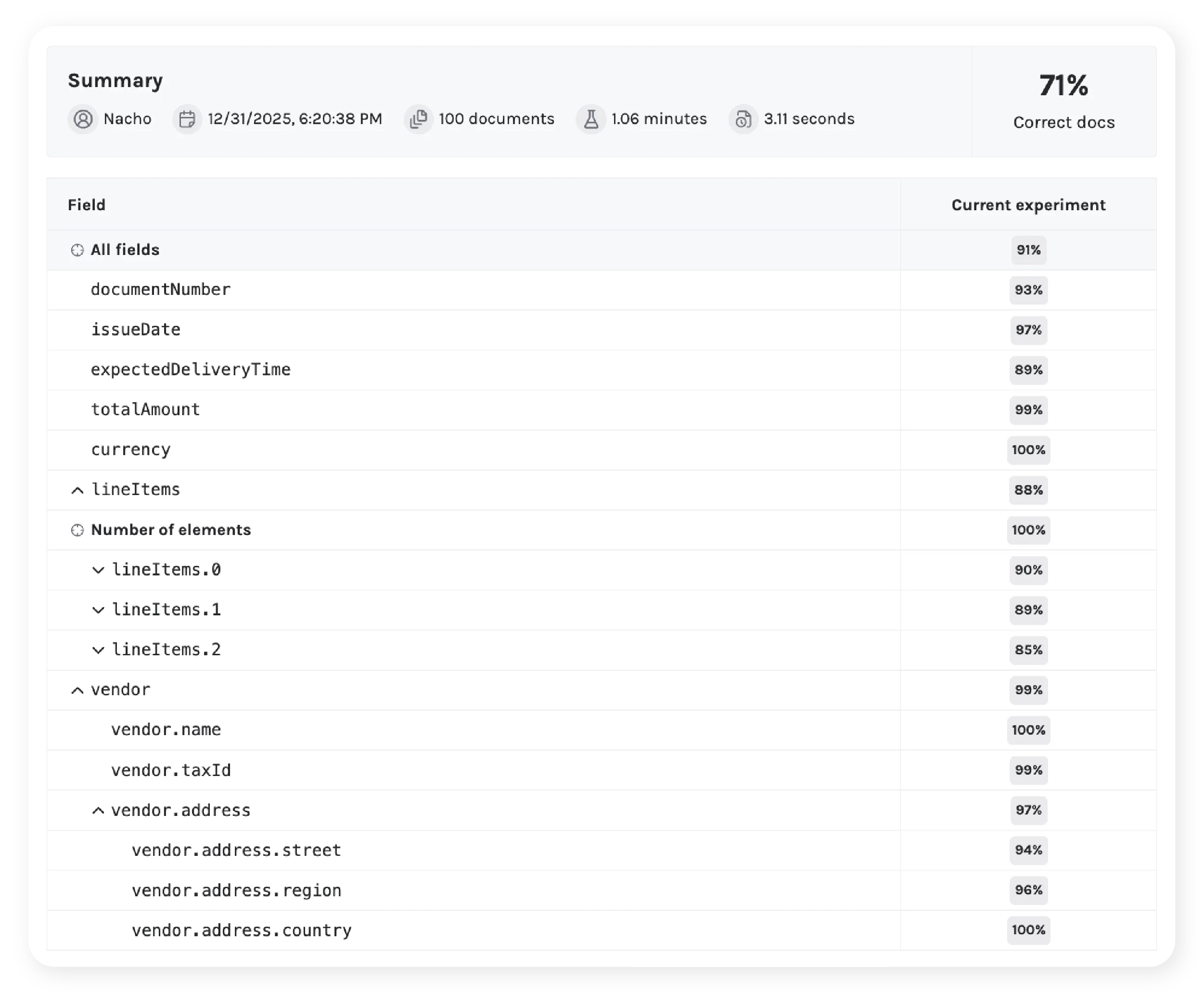
Inspecciona los mismatches contra el ground truth.
En cada experimento, los valores extraídos se comparan directamente contra el ground truth. Los mismatches se clasifican en categorías de error explícitas — los modos de fallo se vuelven visibles y accionables.
Categorías de error
- Ruido de OCR y errores a nivel de carácter
- Valores semánticamente equivalentes pero expresados de forma distinta
- Asignación incorrecta de campos o valores faltantes
- Problemas estructurales en campos anidados o arrays
Ajustes dirigidos
-
Extracción focalizada
Separar esquemas complejos para que distintos modelos extraigan secciones específicas.
-
Procesado del input
Convertir inputs a HTML o Markdown para alinear mejor con el comportamiento del modelo.
-
Refinamiento por campo
Aplicar normalización, post-procesado o lógica custom a los campos inestables.
-
Especialización del modelo
Correr modelos distintos, fine-tuned por tipo de documento o caso de uso.
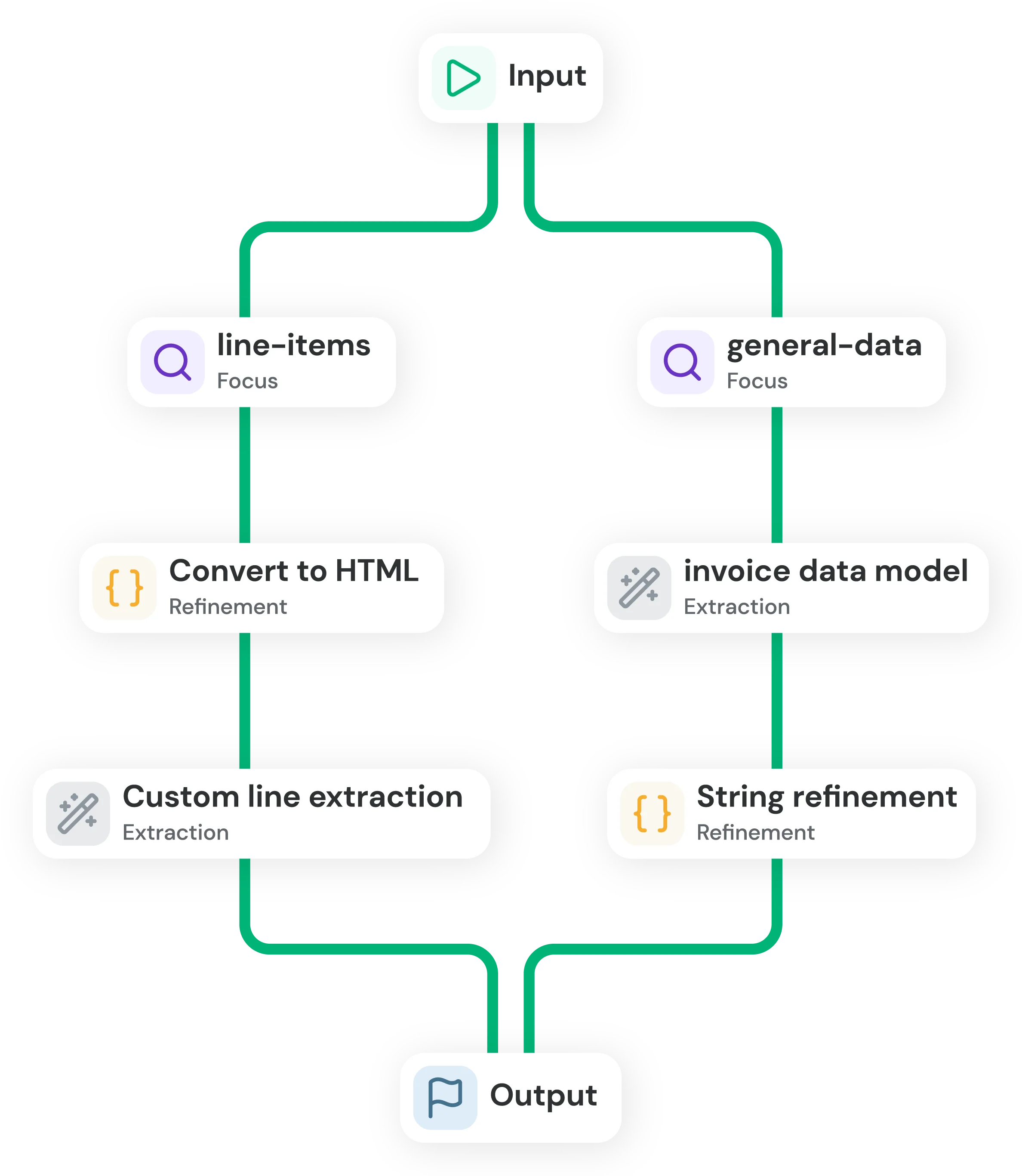
Itera hasta estabilizar la precisión en condiciones de producción.
Los pipelines no están listos cuando un experimento aislado se ve bien — están listos cuando aguantan la realidad caótica del tráfico de producción.
- Incorporar correcciones y feedback del cliente a las nuevas iteraciones
- Monitorizar las tendencias de precisión y detectar regresiones a tiempo
- Adaptar los pipelines automáticamente a medida que documentos y requisitos evolucionan
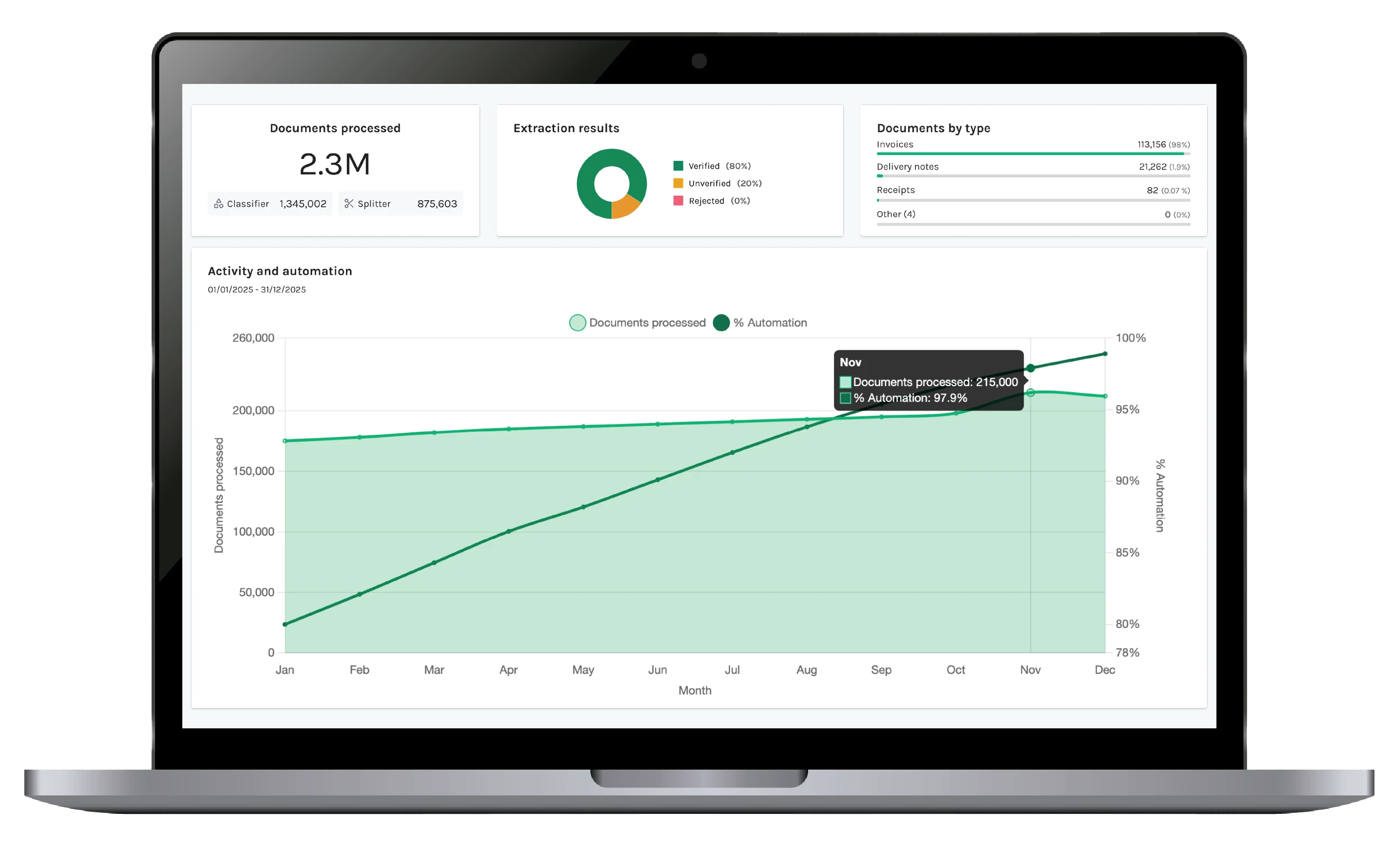
La experimentación es el backbone del document AI en producción.
La mayoría de sistemas de document AI se evalúan en aislamiento sobre inputs limpios y condiciones ideales. Pero la producción se rompe cuando los documentos vienen mezclados, los layouts cambian y los esquemas evolucionan. Este workflow existe para cerrar esa brecha — haciendo de la experimentación parte integral de la plataforma, no un paso offline. El resultado: equipos que pueden…
-
Entender por qué cambia la precisión
Cada cambio es rastreable a una causa específica — modelo, esquema, layout, datos.
-
Detectar regresiones antes de producción
Capturar los problemas durante la experimentación, no cuando los reporta un cliente.
-
Validar contra variabilidad real
Rendimiento probado sobre data real de cliente — no muestras cherry-picked.
-
Promover pipelines con confianza
Adoptar nuevos releases de modelo de forma segura, con evidencia clara detrás de cada cambio.
Capacidades relacionadas de la plataforma.
classifier.json
1 {
2 ··"question": "Classifier & Splitter",
3
4 ··"answer": "Separa y clasifica documentos mezclados para que la extracción arranque desde inputs limpios. Saber más →"
5 }
¿Aún tienes dudas? Habla con nosotros