

11.20.2025
min read


Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra ornare, eros dolor interdum nulla, ut commodo diam libero vitae erat. Aenean faucibus nibh et justo cursus id rutrum lorem imperdiet. Nunc ut sem vitae risus tristique posuere.
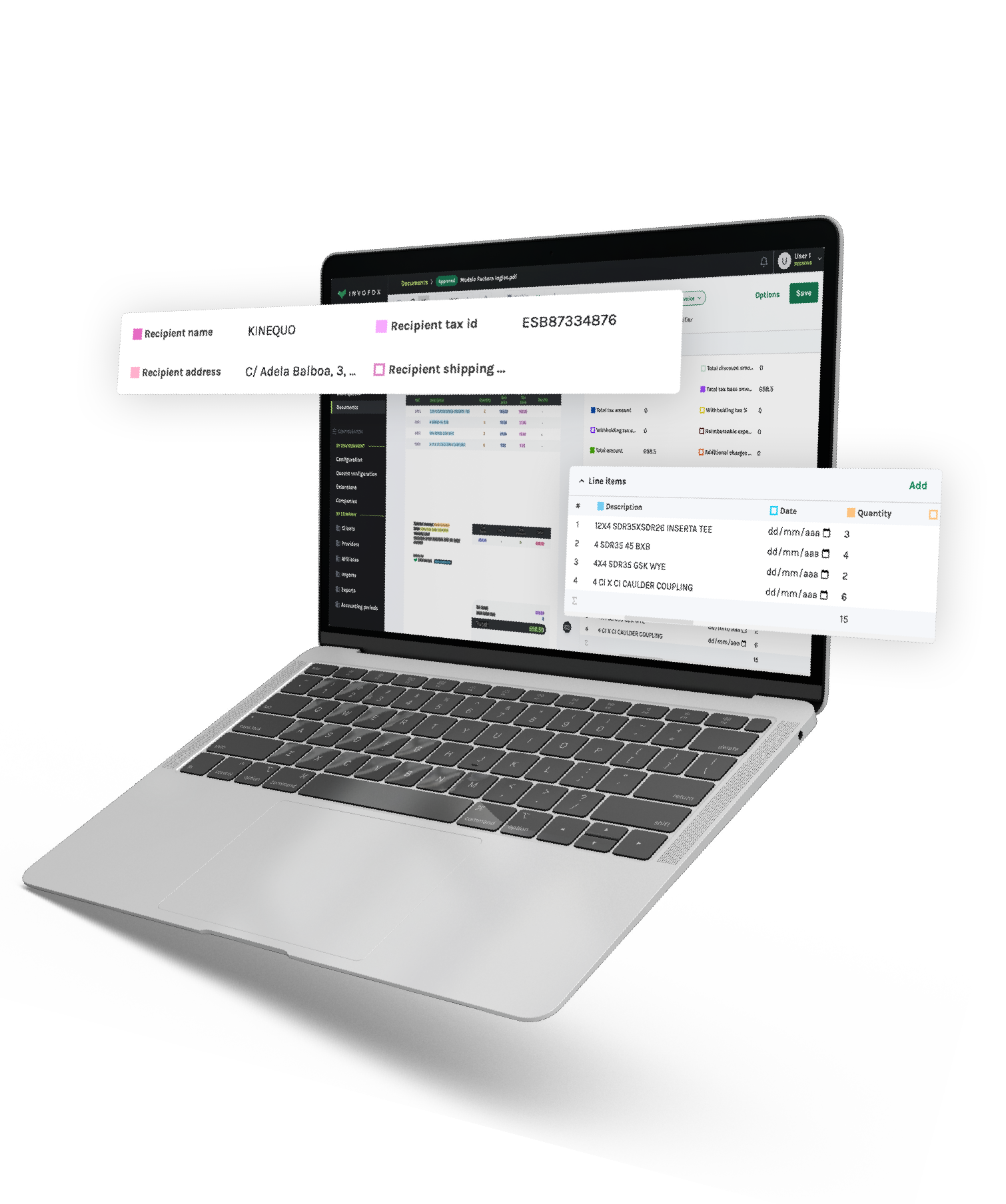
Companies today are drowning in unstructured documents — PDFs, invoices, receipts, contracts, insurance packets, loan files, onboarding forms, and scanned records that show up in every imaginable layout and condition. Every team wants the same outcome: a dependable way to transform that chaos into clean, structured data that can flow easily into ERPs, CRMs, underwriting tools, or analytics.
Every organization faces the same dilemma. Should we build our own intelligent document processing capability or buy a proven platform?
Modern AI and open APIs have made it easier to experiment with intelligent data capture. You can spin up a proof of concept in days using open APIs, vendor-supplied OCR, or a large language model. But what most teams discover is that getting a demo to work is not the hard part. The challenge begins the moment accuracy, speed, stability, or scale actually matter.
This is the real “build versus buy document processing” decision point. Not when you write a quick script that extracts a few fields, but when you realize that production document processing is a constantly shifting landscape of new layouts, degraded scans, compliance requirements, uptime demands, and accuracy drift.
It’s at this stage that most teams start underestimating what “building our own” truly entails. The hidden work goes far beyond OCR. You need splitting and classification, data parsing and extraction, validation against business rules, exception handling, quality assurance, reprocessing, human-in-the-loop tools, model monitoring, and continuous improvement.
Invofox is purpose-built for this production reality, designed to eliminate the operational burden that internal builds inevitably take on while raising accuracy for the documents you care about most.
Let’s break down what is involved and why many teams start with build, then switch to buy.
When teams begin building internal document automation, the initial goal feels simple: extract totals and line items from invoices, names and dates from contracts, or fields from claims. But the moment teams move past clean PDFs and into real-world production files, complexity explodes.
At a technical level, even a basic working internal pipeline requires design work, evaluation datasets, annotation guidelines, quality benchmarks, exception-handling UI, OCR and LLM integrations, fallback rules, and infrastructure to evaluate new documents. These steps come long before any meaningful ROI.
The documents themselves are the next surprise. Invoices and contracts look structured but vary by vendor, region, language, and process. Templates change after mergers. Scan quality shifts from clean PDFs to phone photos. Many files include stamps, signatures, or watermarks that confuse models. You also meet handwritten notes, nonstandard tables, nested columns, and multi-document packets inside one PDF. And these are the norm — not the edge cases.
OCR accuracy also degrades when noise increases. Layout-aware extraction helps, but they are sensitive to formatting shifts, hallucination risk, and unstructured white space. Even strong teams spend quarters cleaning data, labeling edge cases, and retraining models that still fail to generalize across document types.
This is the fundamental difference between OCR vs IDP. OCR extracts text. IDP (Intelligent Document Processing) orchestrates splitting, classification, extraction, parsing, validation, evaluation, correction, and retraining. And that orchestration is the part most teams underestimate.
As layouts change and new document types appear, internal pipelines start breaking silently. Fixing them requires new labels, model updates, regression testing, redeployment, and constant monitoring to ensure accuracy hasn’t declined in the background. Even when teams get something working, they quickly discover that maintaining accuracy is far harder than achieving it once.
It’s easy to build a proof of concept. It’s hard to build something that survives production.
Scale exposes fragility. Each new vendor, template, or document type becomes a mini project that needs labels, rules, and careful evaluation. Layout shifts break parsing logic. Fixes require relabeling, revalidating, and redeploying. Maintaining accuracy across thousands of pages and dozens of templates turns into a full-time job. The ingestion pipeline that seemed simple becomes a web of services, queues, and scripts that only a few engineers understand — which also becomes a major risk when those engineers rotate teams or leave.
This is why many teams discover that building isn’t the real challenge.Maintaining is.
These are the same challenges Invofox was designed to eliminate by unifying OCR, LLMs, business-rule validation, and human-in-the-loop review in one continuously learning pipeline.
Most teams begin with good intentions. They want control and deep customization. They want data ownership and freedom from licensing. They expect to tailor extraction to exact schemas, reduce vendor lock-in, and keep sensitive data under their governance.
Months later the reality hits.
Internal document-processing pipelines need roadmaps, QA cycles, versioning, regression checks, annotation strategy, business-rule updates, and long-term ownership. Without that investment, accuracy and reliability degrade quickly. And because internal tools rarely receive the same attention as customer-facing products, they fall behind rapidly.
Most teams do not fail to build. They fail to maintain.
The question is not whether you can build. The question is whether maintaining and scaling that build will deliver a better return than partnering with a platform designed for it.
Building can fit highly specific or IP-sensitive use cases that no vendor can match. But for most teams, months disappear into maintaining integrations, debugging pipelines, and guessing whether accuracy is improving.
Invofox delivers what matters most. Accuracy, measurable results, and freedom from infrastructure management.
Teams often underestimate how many separate systems must be built (and constantly maintained) to run document processing at production scale. A complete internal system requires:
Each item behaves like a mini platform. Combined, the total cost of ownership rises quickly, even before onboarding flows, user permissions, and self-serve tools for operations and finance.
Production quality is expensive. Maintaining performance parity with top IDP platforms requires MLOps infrastructure, data ops staff, DevOps support, ML engineers, and product oversight — easily reaching millions over several years.
And this entire system still risks falling behind vendors who benefit from cross-customer learning signals that no individual company can replicate.
The decision to build your own document-processing pipeline has significant cost and risk implications that extend well beyond initial development. Production-grade accuracy, drift prevention, monitoring, and compliance all carry ongoing operational expenses that compound over time. Understanding the true cost structure is essential to evaluating whether an internal build creates or destroys long-term ROI.
Buying provides predictable spend with transparent usage-based pricing, faster time to value, and continuous upgrades without lift from your team.
But unlike most “buy” solutions, Invofox is truly API-first. Most IDP vendors still require you to build pipelines, configure vendor integrations, create validation flows, or maintain evaluation logic. With Invofox, everything flows through one endpoint and one webhook — ingestion, splitting, classification, parsing, extraction, and continuous learning. Your developers don’t have to stitch anything together. They simply send documents and receive structured, validated data back.
Invofox does not depend on a single vendor or model. The platform selects the best tool for the page or field, blends extraction with validation against business rules, and reconciles conflicts. Every processed document contributes learning signals that raise accuracy across similar documents. Customers see the results in fewer exceptions, lower handling times, and cleaner downstream data. In an IDP platform comparison, this cross-vendor learning is a decisive edge.
The operational loop is simple to state and hard to run alone. Documents move through parsing and validation. Corrections are captured. The system retrains on those examples. The next batch benefits from the last batch. Over time the platform becomes faster and more accurate.
Production IDP cannot be a black box. Invofox provides full visibility into model performance over time so you can benchmark progress. Accuracy, manual review reduction, and processing speed are all backed by measurable data.
Invofox delivers the full stack in under a day. Ingestion, splitting, classification, parsing, extraction, validation, and delivery all flow through a single endpoint and webhook — no pipeline to build or maintain. You keep control over your data and architecture while skipping recruiting, building, and maintaining a document ingestion pipeline and compliance program. You also accelerate every initiative that depends on reliable structured data.
If you’re deciding between building and buying, the safer path is to choose a platform designed to solve the exact challenges you're about to encounter. Invofox processes millions of documents every month for teams that want reliable, scalable, continuously improving accuracy — without maintaining the infrastructure behind it.
Alberto Gimeno is the CEO and co-founder of Invofox. A computer scientist and mathematician, he worked for years as a developer before moving into sales and co-launching Invofox in 2022. Since then, he has scaled the company to serve over 100 software firms and process tens of millions of business documents each year.
Subscribe for tips and insights from Invofox — the intelligent document processing (IDP) platform that helps businesses automate invoices, receipts, and more.
11.20.2025
min read
Companies today are drowning in unstructured documents — PDFs, invoices, receipts, contracts, insurance packets, loan files, onboarding forms, and scanned records that show up in every imaginable layout and condition. Every team wants the same outcome: a dependable way to transform that chaos into clean, structured data that can flow easily into ERPs, CRMs, underwriting tools, or analytics.
Every organization faces the same dilemma. Should we build our own intelligent document processing capability or buy a proven platform?
Modern AI and open APIs have made it easier to experiment with intelligent data capture. You can spin up a proof of concept in days using open APIs, vendor-supplied OCR, or a large language model. But what most teams discover is that getting a demo to work is not the hard part. The challenge begins the moment accuracy, speed, stability, or scale actually matter.
This is the real “build versus buy document processing” decision point. Not when you write a quick script that extracts a few fields, but when you realize that production document processing is a constantly shifting landscape of new layouts, degraded scans, compliance requirements, uptime demands, and accuracy drift.
It’s at this stage that most teams start underestimating what “building our own” truly entails. The hidden work goes far beyond OCR. You need splitting and classification, data parsing and extraction, validation against business rules, exception handling, quality assurance, reprocessing, human-in-the-loop tools, model monitoring, and continuous improvement.
Invofox is purpose-built for this production reality, designed to eliminate the operational burden that internal builds inevitably take on while raising accuracy for the documents you care about most.
Let’s break down what is involved and why many teams start with build, then switch to buy.
When teams begin building internal document automation, the initial goal feels simple: extract totals and line items from invoices, names and dates from contracts, or fields from claims. But the moment teams move past clean PDFs and into real-world production files, complexity explodes.
At a technical level, even a basic working internal pipeline requires design work, evaluation datasets, annotation guidelines, quality benchmarks, exception-handling UI, OCR and LLM integrations, fallback rules, and infrastructure to evaluate new documents. These steps come long before any meaningful ROI.
The documents themselves are the next surprise. Invoices and contracts look structured but vary by vendor, region, language, and process. Templates change after mergers. Scan quality shifts from clean PDFs to phone photos. Many files include stamps, signatures, or watermarks that confuse models. You also meet handwritten notes, nonstandard tables, nested columns, and multi-document packets inside one PDF. And these are the norm — not the edge cases.
OCR accuracy also degrades when noise increases. Layout-aware extraction helps, but they are sensitive to formatting shifts, hallucination risk, and unstructured white space. Even strong teams spend quarters cleaning data, labeling edge cases, and retraining models that still fail to generalize across document types.
This is the fundamental difference between OCR vs IDP. OCR extracts text. IDP (Intelligent Document Processing) orchestrates splitting, classification, extraction, parsing, validation, evaluation, correction, and retraining. And that orchestration is the part most teams underestimate.
As layouts change and new document types appear, internal pipelines start breaking silently. Fixing them requires new labels, model updates, regression testing, redeployment, and constant monitoring to ensure accuracy hasn’t declined in the background. Even when teams get something working, they quickly discover that maintaining accuracy is far harder than achieving it once.
It’s easy to build a proof of concept. It’s hard to build something that survives production.
Scale exposes fragility. Each new vendor, template, or document type becomes a mini project that needs labels, rules, and careful evaluation. Layout shifts break parsing logic. Fixes require relabeling, revalidating, and redeploying. Maintaining accuracy across thousands of pages and dozens of templates turns into a full-time job. The ingestion pipeline that seemed simple becomes a web of services, queues, and scripts that only a few engineers understand — which also becomes a major risk when those engineers rotate teams or leave.
This is why many teams discover that building isn’t the real challenge.Maintaining is.
These are the same challenges Invofox was designed to eliminate by unifying OCR, LLMs, business-rule validation, and human-in-the-loop review in one continuously learning pipeline.
Most teams begin with good intentions. They want control and deep customization. They want data ownership and freedom from licensing. They expect to tailor extraction to exact schemas, reduce vendor lock-in, and keep sensitive data under their governance.
Months later the reality hits.
Internal document-processing pipelines need roadmaps, QA cycles, versioning, regression checks, annotation strategy, business-rule updates, and long-term ownership. Without that investment, accuracy and reliability degrade quickly. And because internal tools rarely receive the same attention as customer-facing products, they fall behind rapidly.
Most teams do not fail to build. They fail to maintain.
The question is not whether you can build. The question is whether maintaining and scaling that build will deliver a better return than partnering with a platform designed for it.
Building can fit highly specific or IP-sensitive use cases that no vendor can match. But for most teams, months disappear into maintaining integrations, debugging pipelines, and guessing whether accuracy is improving.
Invofox delivers what matters most. Accuracy, measurable results, and freedom from infrastructure management.
Teams often underestimate how many separate systems must be built (and constantly maintained) to run document processing at production scale. A complete internal system requires:
Each item behaves like a mini platform. Combined, the total cost of ownership rises quickly, even before onboarding flows, user permissions, and self-serve tools for operations and finance.
Production quality is expensive. Maintaining performance parity with top IDP platforms requires MLOps infrastructure, data ops staff, DevOps support, ML engineers, and product oversight — easily reaching millions over several years.
And this entire system still risks falling behind vendors who benefit from cross-customer learning signals that no individual company can replicate.
The decision to build your own document-processing pipeline has significant cost and risk implications that extend well beyond initial development. Production-grade accuracy, drift prevention, monitoring, and compliance all carry ongoing operational expenses that compound over time. Understanding the true cost structure is essential to evaluating whether an internal build creates or destroys long-term ROI.
Buying provides predictable spend with transparent usage-based pricing, faster time to value, and continuous upgrades without lift from your team.
But unlike most “buy” solutions, Invofox is truly API-first. Most IDP vendors still require you to build pipelines, configure vendor integrations, create validation flows, or maintain evaluation logic. With Invofox, everything flows through one endpoint and one webhook — ingestion, splitting, classification, parsing, extraction, and continuous learning. Your developers don’t have to stitch anything together. They simply send documents and receive structured, validated data back.
Invofox does not depend on a single vendor or model. The platform selects the best tool for the page or field, blends extraction with validation against business rules, and reconciles conflicts. Every processed document contributes learning signals that raise accuracy across similar documents. Customers see the results in fewer exceptions, lower handling times, and cleaner downstream data. In an IDP platform comparison, this cross-vendor learning is a decisive edge.
The operational loop is simple to state and hard to run alone. Documents move through parsing and validation. Corrections are captured. The system retrains on those examples. The next batch benefits from the last batch. Over time the platform becomes faster and more accurate.
Production IDP cannot be a black box. Invofox provides full visibility into model performance over time so you can benchmark progress. Accuracy, manual review reduction, and processing speed are all backed by measurable data.
Invofox delivers the full stack in under a day. Ingestion, splitting, classification, parsing, extraction, validation, and delivery all flow through a single endpoint and webhook — no pipeline to build or maintain. You keep control over your data and architecture while skipping recruiting, building, and maintaining a document ingestion pipeline and compliance program. You also accelerate every initiative that depends on reliable structured data.
If you’re deciding between building and buying, the safer path is to choose a platform designed to solve the exact challenges you're about to encounter. Invofox processes millions of documents every month for teams that want reliable, scalable, continuously improving accuracy — without maintaining the infrastructure behind it.
Alberto Gimeno is the CEO and co-founder of Invofox. A computer scientist and mathematician, he worked for years as a developer before moving into sales and co-launching Invofox in 2022. Since then, he has scaled the company to serve over 100 software firms and process tens of millions of business documents each year.



Subscribe for tips and insights from Invofox — the intelligent document processing (IDP) platform that helps businesses automate invoices, receipts, and more.
Used by 150+ companies. We’ll onboard you in 24h.





